Was dich erwartet: Der kurze Überblick
Du gibst einen Text ein – und Sekunden später erscheint ein Bild, das genau das zeigt, was du beschrieben hast. Was wie Magie wirkt, ist in Wahrheit hochkomplexe Mathematik und Machine Learning. In diesem Artikel nehme ich dich mit auf eine Reise unter die Haube der modernen KI-Bildgeneratoren. Du erfährst, wie aus zufälligem Rauschen ein fotorealistisches Bild wird, was „Diffusion“ wirklich bedeutet und warum DALL-E, Midjourney und Stable Diffusion so erstaunliche Ergebnisse liefern können. Keine Sorge – ich erkläre alles so, dass du es verstehst, auch ohne Informatikstudium.
Wie aus Rauschen Katzen werden: Diffusionsmodelle verstehen
Stell dir vor, du hast ein perfektes Foto einer Katze. Jetzt nimmst du einen Radiergummi und löschst nach und nach immer mehr Details, bis nur noch ein chaotisches Rauschen übrig bleibt – wie Schnee auf einem alten Fernseher. Genau diesen Prozess lernen moderne KI-Systeme – nur rückwärts!
Was ist ein Diffusionsmodell?
Ein Diffusionsmodell ist wie ein Zauberer, der gelernt hat, aus Chaos Ordnung zu schaffen. Der technische Prozess läuft in zwei Phasen ab:
- Training (Vorwärts-Diffusion): Die KI bekommt Millionen von Bildern zu sehen. Sie lernt, wie man diesen schrittweise Rauschen hinzufügt, bis nur noch Chaos übrig ist.
- Generierung (Rückwärts-Diffusion): Nach dem Training kann die KI den Prozess umkehren! Sie startet mit zufälligem Rauschen und entfernt Schritt für Schritt das „Chaos“, bis ein sauberes Bild entsteht.
Das Geniale daran: Da die KI gelernt hat, wie Katzen, Berge oder Menschen aussehen sollten, kann sie aus purem Rauschen wieder solche Bilder rekonstruieren – auch wenn sie genau dieses Bild noch nie gesehen hat!

Die mathematische Magie dahinter
Im Kern arbeiten Diffusionsmodelle mit etwas, das Mathematiker als „stochastische Differentialgleichungen“ bezeichnen. Keine Panik – vereinfacht gesagt geht es darum, kleine, kalkulierte Änderungen vorzunehmen, die von einem zufälligen Zustand zu einem strukturierten Bild führen.
Bei jedem Schritt der Rückwärts-Diffusion fragt sich die KI: „Wenn ich hier bin und ein Katzenbild erzeugen will – welche Pixel sollte ich als Nächstes anpassen?“ Und das tut sie hunderte Male, bis aus dem Rauschen langsam eine Katze entsteht.
Vom Text zum Bild: So funktioniert die Pipeline
Wenn du bei DALL-E oder Midjourney einen Prompt eingibst, durchläuft deine Anfrage mehrere Verarbeitungsschritte:
1. Prompt-Verarbeitung
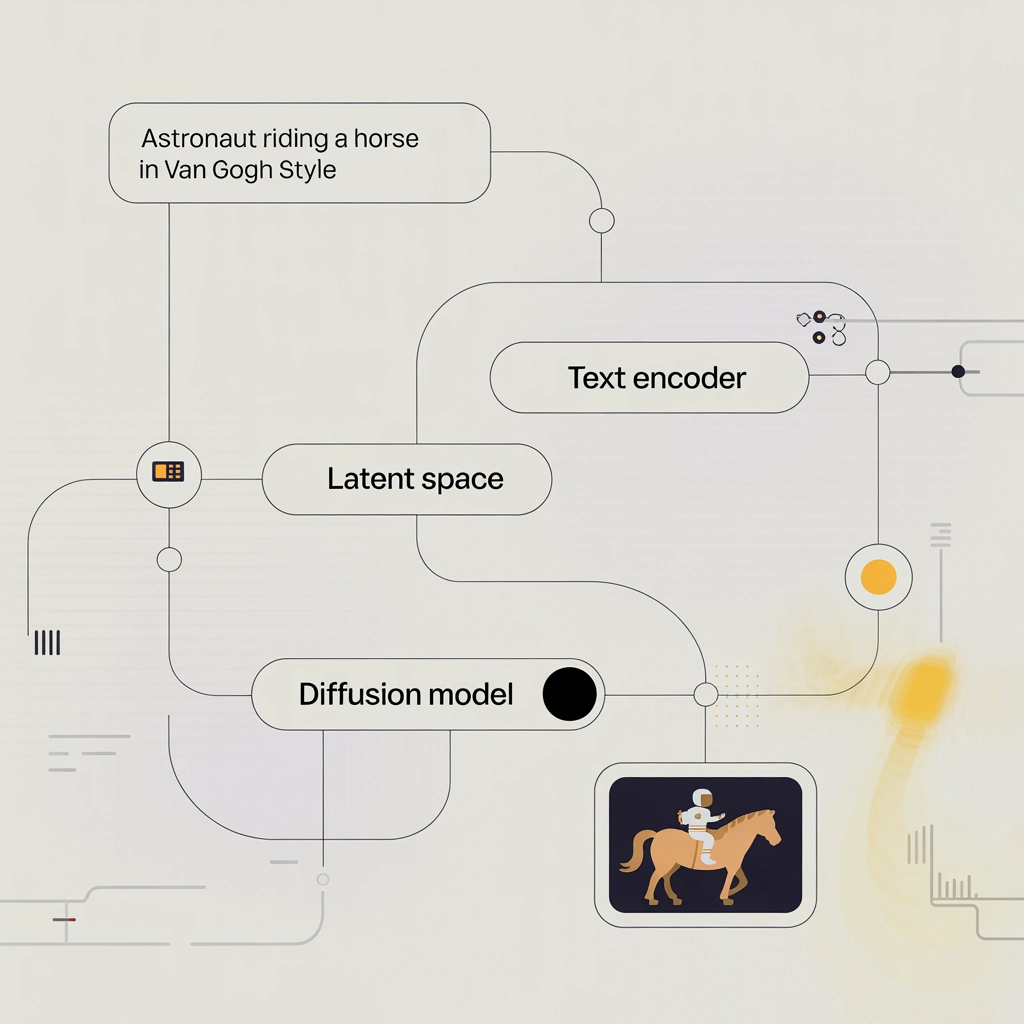
Zunächst wird dein Text (z.B. „Ein Astronaut reitet auf einem Pferd im Stil von Van Gogh“) durch ein Sprachmodell analysiert. Dieses extrahiert relevante Konzepte und wandelt sie in einen numerischen Vektor um – einen „Textembedding“.
2. Latent Space Mapping
Diese Textembeddings werden dann in einen gemeinsamen „Latent Space“ mit Bildern projiziert. Denk dir den Latent Space wie eine mathematische Dimension, in der ähnliche Konzepte nahe beieinander liegen. Der Text „roter Sportwagen“ liegt dort nahe bei Bildern von roten Sportwagen.
3. Der Diffusionsprozess startet
Jetzt beginnt die eigentliche Bildgenerierung:
- Die KI erzeugt zufälliges Rauschen
- In typischerweise 50-1000 Schritten wird dieses Rauschen schrittweise „entlärmt“
- Bei jedem Schritt fließen die Informationen aus dem Textembedding ein
- Das Diffusionsmodell „rät“, welche Pixel wie verändert werden sollten
4. Upscaling und Feinschliff
Das erste generierte Bild hat oft eine niedrige Auflösung. Zusätzliche Modelle skalieren es hoch und fügen Details hinzu.
Was steckt wirklich in Stable Diffusion & Co.?
Die populärsten KI-Bildgeneratoren nutzen ähnliche, aber doch unterschiedliche Ansätze:
Stable Diffusion: Latente Diffusion
Stable Diffusion, entwickelt von Stability AI, revolutionierte die Szene durch seinen Open-Source-Ansatz. Seine Besonderheit:
- Arbeitet nicht direkt mit Pixeln, sondern mit komprimierten Darstellungen (latenter Raum)
- Dadurch braucht es weniger Rechenleistung – läuft sogar auf leistungsstarken Heimcomputern
- Nutzt einen VAE (Variational Autoencoder) zur Kompression und Dekompression
- Der eigentliche Diffusionsprozess findet im komprimierten Raum statt
Die vereinfachte Architektur:
- VAE-Encoder komprimiert Bilder in den latenten Raum
- U-Net-Diffusionsmodell bearbeitet diese komprimierte Darstellung
- CLIP-Textencoder verarbeitet den Prompt
- VAE-Decoder wandelt die latente Darstellung zurück in ein Bild
DALL-E und Midjourney: Unterschiede und Gemeinsamkeiten
DALL-E 2 und 3 (von OpenAI) sowie Midjourney nutzen ebenfalls Diffusionstechnologie, aber mit eigenen Erweiterungen:
- DALL-E 3 ist direkter mit GPT-4 integriert, was komplexere Prompts ermöglicht
- Midjourney verwendet eigene Verfeinerungen für besonders ästhetische Ergebnisse
- Alle drei Systeme haben unterschiedliche Trainingsdaten, was ihre „Stile“ beeinflusst
Die heimlichen Helden: Attention und Transformer
Ein wichtiger Baustein moderner Bildgeneratoren sind Attention-Mechanismen – dieselbe Technologie, die auch ChatGPT antreibt.
Attention erlaubt es der KI, Beziehungen zwischen weit entfernten Teilen des Bildes herzustellen. Wenn im Prompt „ein Mann mit rotem Hut“ steht, hilft Attention dabei, dass der Hut tatsächlich rot wird und zum Mann gehört – nicht irgendwo anders im Bild auftaucht.
Die neuesten Modelle nutzen Cross-Attention, um Text- und Bildinformationen zu verknüpfen. Diese Technik ermöglicht die präzise Umsetzung von Textbeschreibungen in visuelle Elemente.
Trainingsdaten: Die verborgene Grundlage
Hinter jedem KI-Modell stehen gigantische Datenmengen. Stable Diffusion wurde beispielsweise mit LAION-5B trainiert – einer Datenbank mit 5,85 Milliarden Bild-Text-Paaren!
Diese Daten bestimmen maßgeblich, was die KI „kann“ und was nicht:
- Hat sie viele Anime-Bilder gesehen? Dann wird sie gut darin sein, Anime zu generieren.
- Wurde sie mit Gemälden berühmter Künstler trainiert? Dann kann sie deren Stile nachahmen.
Das Training selbst dauert Wochen auf Hochleistungs-GPU-Clustern und verbraucht enorme Mengen Energie.

Der Weg von der Theorie zum fertigen Bild
Um das Ganze greifbarer zu machen, hier ein konkretes Beispiel:
- Du gibst ein: „Ein futuristisches Unterwasser-Restaurant bei Nacht mit Neonlichtern“
- Der Text-Encoder verarbeitet deinen Prompt und erzeugt einen numerischen Vektor
- Ein Rauschgenerator erzeugt zufälliges Pixelrauschen
- Das Diffusionsmodell beginnt, das Rauschen zu entfernen, Schritt für Schritt:
- Bei Schritt 1 (von 50) ist noch kaum etwas erkennbar
- Bei Schritt 10 zeichnen sich grobe Formen ab
- Bei Schritt 25 wird klar: Das ist ein Unterwasser-Setting
- Bei Schritt 40 sind Details wie Tische, Fenster und Neonlichter sichtbar
- Bei Schritt 50 ist das finale Bild fertig
- Optional werden noch Upscaling und Detailverbesserungen durchgeführt
Das Faszinierende dabei: Die KI kennt keine Konzepte wie „Restaurant“ oder „Neon“. Sie hat nur gelernt, welche Pixelmuster typischerweise mit diesen Wörtern assoziiert werden.
Die Zukunft der KI-Bildgenerierung
Die Technologie entwickelt sich rasant weiter. Aktuelle Trends:
- Personalisierung: Trainiere ein Modell mit wenigen Bildern deiner selbst, um dann in beliebigen Szenarien zu erscheinen
- Animation: Aus Standbildern werden Videoclips (wie bei Runway ML)
- 3D-Generierung: Direkte Erzeugung von 3D-Modellen statt nur 2D-Bildern
- Editierbare Ergebnisse: Präzisere Kontrolle über einzelne Bildelemente
Fazit: Die Kunst des digitalen Rauschens
Was vor wenigen Jahren noch Science-Fiction war, ist heute Realität. KI-Bildgenerierung durch Diffusionsmodelle hat die kreative Welt revolutioniert. Die Technologie dahinter – von der Vorwärts- und Rückwärts-Diffusion bis hin zu komplexen Attention-Mechanismen – ist ein beeindruckendes Beispiel dafür, wie mathematische Modelle kreative Prozesse nachbilden können.
Auf unserem YouTube-Kanal der Nerdoase findest du weitere praktische Tutorials, wie du diese Tools optimal nutzen kannst. Und falls dich das Thema KI generell interessiert, schau unbedingt in unsere anderen Artikel zum Thema maschinelles Lernen und künstliche Intelligenz auf unserem Blog.
Die Grenzen zwischen menschlicher und KI-generierter Kreativität verschwimmen zunehmend – und wir stehen erst am Anfang dieser Entwicklung. Bleib neugierig!
Nerdfakt zum Abschluss: Die Mathematik hinter Diffusionsmodellen geht auf Forschungen zur Thermodynamik zurück – die gleichen Prinzipien, die beschreiben, wie sich Tinte in Wasser verteilt, helfen nun dabei, digitale Kunstwerke zu erschaffen!
Schreibe einen Kommentar